End-to-End Object Detection with Transformers Direct Set Prediction
Novelty: Object Detection as a direct set prediction problem. How efficient is the reformulation? Let’s find out.

<Prior methods:> Current object detection pipelines include hand-crafted components like spatial anchor generation and non-max suppression (NMS). Each of these components is tuned specifically for a given task. For example, NMS is threshold-based and requires an IOU (intersection over union) and confidence threshold tuning to be able to effectively discard the overlapping bounding boxes.
This task specificity of different components in the traditional object detection pipeline is inconvenient. This approach provides a simpler formulation of the underlying concepts. Some previous approaches have tried to formulate object detection as a set prediction task and were using autoregressive architecture such as RNNs (computationally intensive and didn’t efficiently capture all global dependencies). Transformers are better at capturing these dependencies using attention mechanisms. This is the first use of transformers in a set prediction task.
Overview
- Understanding Set Prediction Loss
- Architecture Overview [Encoder-Decoder simplification for understanding]
- Results
- Interesting Directions
- Summary
1. Understanding Set Prediction Loss
DETR generates a set of (N) fixed-size predictions, in a single pass through the decoder. N is chosen to be larger than the typical number of objects in an image. Each element of this set is a prediction for class and bounding box specification for an object, as shown below:
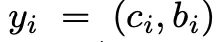
<Difficulty:> To score predicted object (class, position, size) with respect to the ground truth.
<Solution:> Bipartite matching (predictions and ground truth) and optimization of bounding box specific losses.
2. Bi-Partite Matching
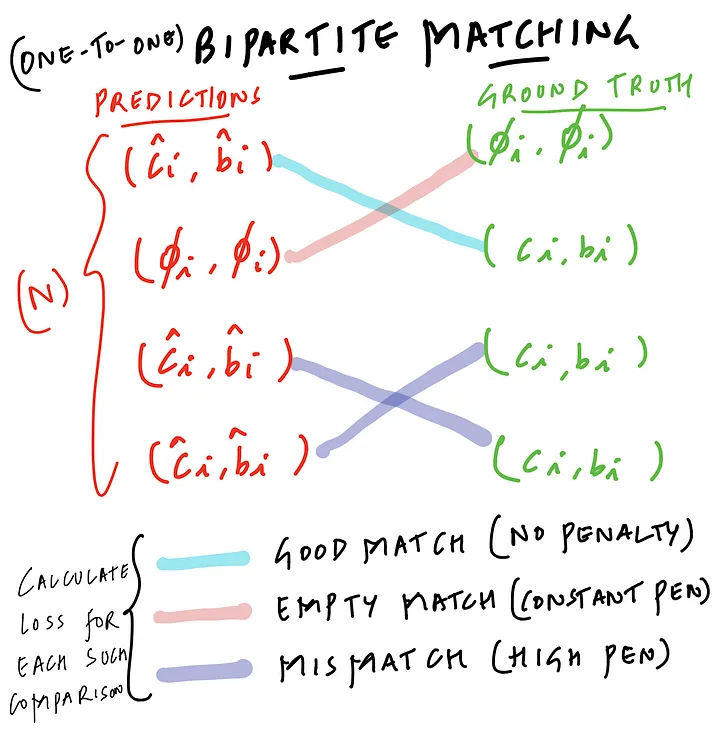
Search for permutation of N elements with the lowest cost. L_{match} refers to the pair-wise matching cost. This approach is ‘order’ agnostic. Optimal matching is calculated using the Hungarian algorithm. Takes both class and boxes into consideration.
The process of matching is similar to heuristic processes used in previous work where we match region proposals or anchors to the ground truth objects. The only difference being, in this case, by design we impose a one-to-one matching.
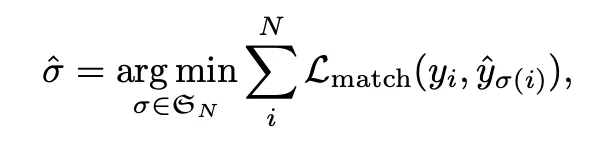
Calculate the loss of all matched pairs. Negative log-likelihood of the class prediction and the box loss.
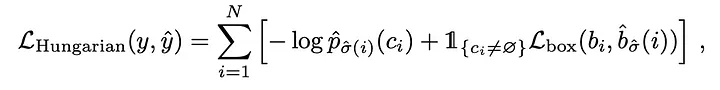
3. Bounding box loss
Box loss concerns: The most commonly-used L1 loss will have different scales for small and large boxes even if their relative errors are similar.
Mitigation: Mitigate this issue using a linear combination of the L1 loss and the generalized IoU loss.
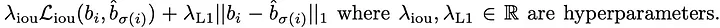
IoU loss is independent of the scale of the bounding boxes, instead, it depends on how well they overlap. As discussed in the paper, experiments performed only using L1 loss produced poor results. Combined loss produced better results. In general, the model performs poor in images with smaller objects when compared to traditional object detection models.
4. Architecture Overview
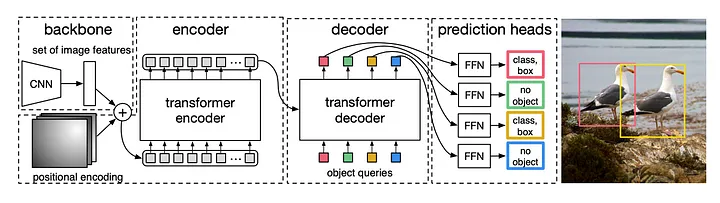
Encoder: Transform image and positional encoding using a transformer. Produce a globally aware representation. Why? In object detection to be able to generate better bounding box predictions, it is important to produce encodings globally aware of spatial dependencies.
Decoder: The output of the encoder is used as conditioning information for the object queries (N). Object queries are simply N random vectors to start off with. Each output of the decoder corresponds to one bounding box, which is further fed into a classifier (3-layer perceptron).
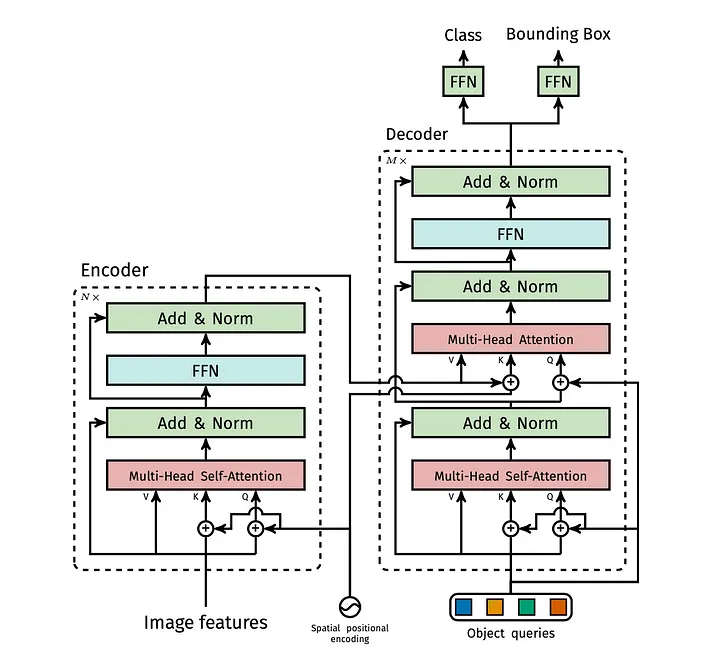
Extreme Simplification: Different query objects can be assumed to be querying the encoded input image in order to produce the desired output. This querying can be thought of as a process of gaining a better spatial localization of objects in the image, given that this information is shared across all query objects. Random vector initializations are conditioned subsequently.
5. Results
COCO 2017 Detection Dataset, containing 118k training images and 5k validation images. On average 7 instances per image. Reported AP.
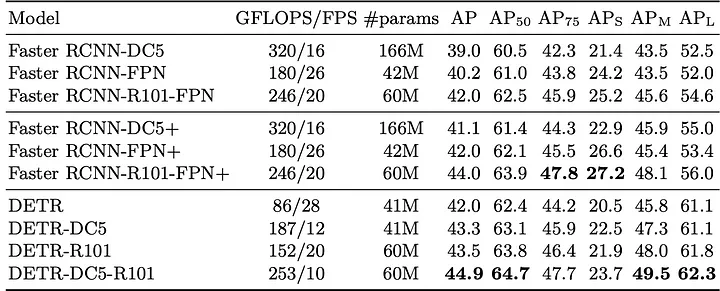
Results demonstrate that the End-to-End transformer architecture results are on par with the current object detection architectures. The paper further goes on the compare the model on a segmentation task.
Challenges: Transformers take very long to train. As discussed in the paper, training the baseline model for 300 epochs on 16 V100 GPUs takes 3 days, with 4 images per GPU (hence a total batch size of 64). For the longer schedule used to compare with Faster R-CNN, we train for 500 epochs with learning rate drop after 400 epochs. Training on small datasets might still be manageable.
6. Interesting Directions
- Attention maps
Can visualize where the network is attending for generating specific bounding box predictions. This can prove useful for identifying model failure conditions visually, in effect, facilitating an understanding of the limitations of the training data. Counters measures can be taken to augment and include those specific cases during the training. Or else we just meet GDPR regulations for transparency ;)

- Improved detection and attention maps

- Out of distribution generalization for rare classes
Out of distribution generalization for rare classes. Even though no image in the training set has more than 13 giraffes, DETR has no difficulty generalizing to 24 and more instances of the same class.

Summary
Pros
- A simplified formulation for object detection pipeline. An efficient iteration over previous autoregressive implementations.
- Provides more flexibility with the use of backbone architectures, doesn’t require custom layers like the one we need in YOLO.
- Relatively less dataset-specific tuning when compared to previous methods with anchors and NMS. The only parameter which needs to be dataset-specific is the average number of objects in an image.
- Comparable performance with existing object detection architectures. Comparable FPS performance, however, doesn’t result in a significant improvement.
- Attention guided explainability. Can be used to design better datasets going forward (if required).
Cons
- Training transformers is a bit of a bottleneck on large datasets.
- Less support for training on custom data. Issues on the GitHub repo show that the architecture can be fine-tuned as well as trained from scratch on custom data.